The evolution of PIM is really the story of how product data has turned from a tool reserved for internal operations into fuel for digital commerce and AI-driven decision-making.
The Evolution of Legacy PIM to AI PIM
Before we dive into the differences and advancements an AI PIM offers, we need to acknowledge that what's missing from that ultra-distilled "what" is the “why” it happened in the first place.
So, let’s walk through it.
The Original Role of PIM: Internal Control
When PIM systems first emerged in the early 2000s, their job was simple: Keep product data organized across internal systems. Perspectives revolved around operational functions and the mindset of "make usre our data is correct and consistent."
At the time, e-commerce was limited, there were far fewer channels to navigate, and product data was mostly static.
So, PIM was designed to do meet the moment in terms of:
- Consolidating product data from ERP systems
- Standardizing fields like SKU, price, dimensions
- Ensuring consistency across catalogs and print materials
E-commerce Expansion: Managing Complexity
As e-commerce scaled, the role of PIM expanded alongside the need for product data to support websites, marketplaces, mobile experiences, and regionally specific catalogs.
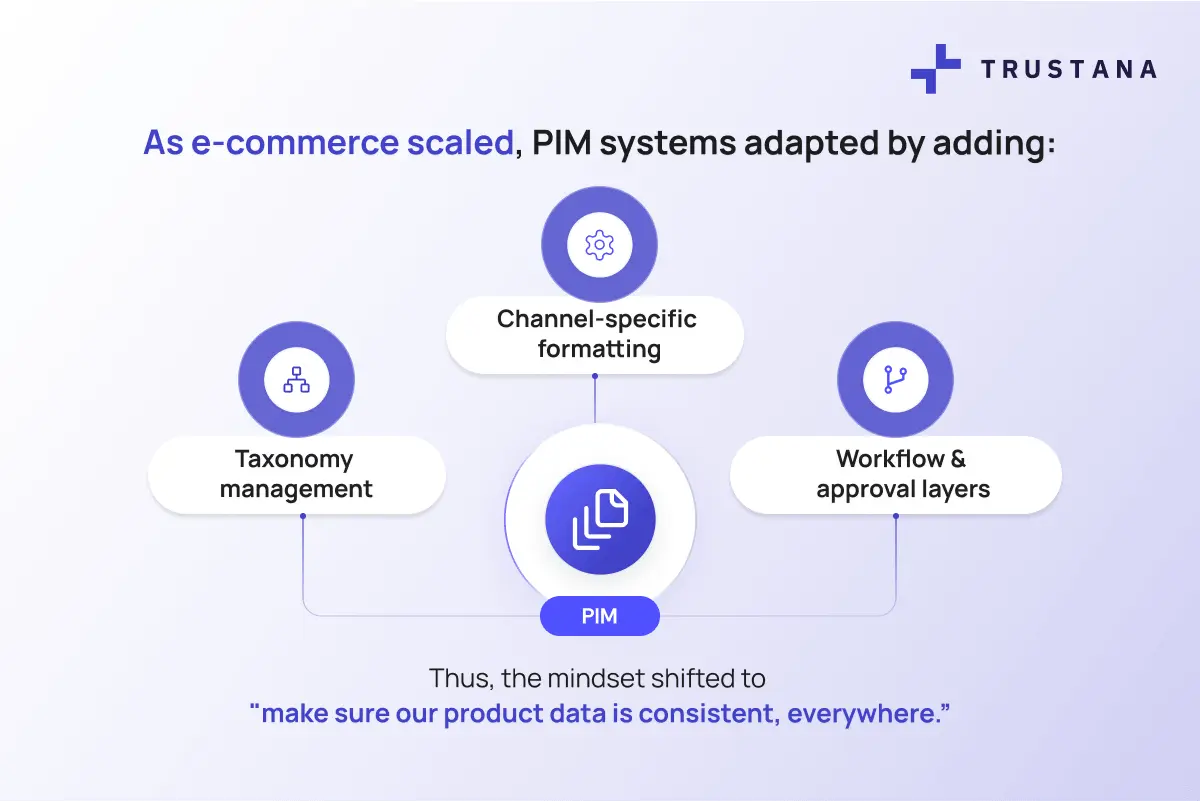
With more SKUs, more channels, and more variations in how product data needed to appear, PIM systems adapted by adding:
- Taxonomy management
- Channel-specific formatting
- Workflow and approval layers
Thus, the mindset shifted to "make sure our product data is consistent, everywhere."
The Breaking Point: Product Dhata Volume + Fragmentation
Product data was relatively easy to manage with a few thousand SKUs but as catalogs scaled into the tens or hundreds of thousands, a new problem emerged: the data itself wasn't good enough.
Teams quickly became mired in incomplete supplier data, inconsistent attributes across sources, generic or duplicate descriptions, and massive manual workloads. As a result, the PIM systems themselves became bottlenecks.
They lost their edge as systems of control because they were asked to do things they were never designed to do, like:
- Create missing data
- Interpret unstructured inputs
- Scale content production
This shifted the thinking for retail and e-commerce teams once more into, "managing the data isn't enough. We need to fix it."
The AI Inflection Point: Product Data Becomes Fuel
E-commerce hit an inflection point with massive catalogs, seemingly endless streams of product data, and the proliferation of marketplaces, like Amazon, Wayfair, and Walmart, requiring strict yet disparate product listing criteria and conformity standards. It made retailers' jobs that much harder to get products onboarded, listed across channels, and in front of shoppers online.
AI stepped onto the scene and introduced incredible tools for discovery in the form of AI search, answer and recommendation engines, and conversational commerce.
The catch was everything hinged on product data for these tools to work. This exposed a critical gap for retailers who thought their PIM systems could address the needs of AI. Most PIM-managed data simply wasn’t usable by AI systems because it didn't have:
- Complete attribute coverage
- Structured, consistent data
- Rich contextual content
- machine-readable formats
The Rise of AI-Native PIM: From Storage to Transformation
This is where the concept of an AI-native PIM emerges.
The way retailers think about product data has shifted from, “How do we manage product data?” to, “How do we continuously improve product data so advanced systems, like LLMs and AI agents, can use it?”
The change was a structural one, where product information evolved from a static element of the business to a dynamic one.
While that product data was initially approached as a “set and forget” asset, the technology modern commerce utilizes demands product data be capable of adapting with consumer trends dynamically.
As part of that shift, dealing with huge amounts of product data can no longer be handled manually. Automation has to come into play. That's where product data enrichment leaves the hands of humans and enters PIM systems built with AI from the ground up, rather than an add-on to an existing platform.
The Missing Layer: AI Enrichment Changes Everything
Most teams don’t realize the core issue isn’t their PIM. It's the fact that it lacks a critical element, one that is necessary to enable and support AI operations interacting with product data.
The Experience:
- Supplier data arrives incomplete
- Attributes are inconsistent across sources
- Descriptions are generic or unusable
- Images lack structure or context
A PIM can store this data but it cannot improve its quality, fill in the missing elements, or fix erroneous information at scale.
What is AI Enrichment?
This is where the enrichment layer comes in.
“Enrichment” can mean very different things depending on who you ask.
In many cases, it refers to a manual service. Teams or external agencies review product data, fill in missing attributes, rewrite descriptions, and standardize fields by hand. This approach can improve quality, but it’s time-intensive, difficult to scale, and often inconsistent across large catalogs. Factor in the cost associated with this approach and it's hardly an idealscenario.
AI-driven product content enrichment is fundamentally different.
Instead of relying on people to fix data one product at a time, it uses systems to process, structure, and improve product data at scale. This includes extracting attributes from unstructured sources like PDFs or images, standardizing values automatically, and generating content in a consistent format.
The difference becomes clear when you look at how the work gets done:
- Manual enrichment depends on human effort and scales with headcount
- AI-driven enrichment uses automation to handle large volumes quickly and consistently
More importantly, AI enrichment is not a one-time activity. It’s an ongoing process that continuously improves product data as new inputs are added or requirements change.
That’s what separates traditional enrichment from an AI-first approach. One is a task. The other is a system.
How Enrichment Contributes to Better Product Data
Instead of just storing data, the enrichment layer actively improves it. This typically includes:
1. Completes missing product data
- Fills attribute gaps
- Standardizes values
- Builds structured fields
2. Translates unstructured inputs into usable data
- PDFs → structured specs
- Images → extracted attributes
- Supplier text → normalized descriptions
3. Creates differentiated product content
- Unique descriptions
- Channel-specific formatting
- SEO and AI-ready language
4. Expands attribute depth for discovery
- Adds filters and facets
- Improves product discovery
- Supports long-tail queries
5. Continuously improves data quality
- Iterative enrichment cycles
- Feedback-driven updates
- Ongoing optimization

When you add the enrichment layer to your workflow, your product data becomes something you can grow, refine, and optimize. It's the difference between a static catalog and a living data foundation.
Structural Comparison: Legacy PIM vs AI PIM + Enrichment Layer
Here’s the full picture, at both the catalog level and the foundational data level:
Static vs Dynamic: The Real Architectural Divide
We touched on this distinction earlier in the article but want to emphasize that this is not just a feature comparison.
There is a structural difference between the two approaches to product data. Here's a simplified comparison:
Legacy PIM = Static Model
- Fixed schemas
- Human-driven updates
- One-time data preparation
AI PIM + Enrichment = Dynamic Model
- Adaptive attributes
- Continuous improvement
- Feedback-driven data evolution
When all's said and done, modern commerce is dynamic, which means your data layer needs to be too.
Why Enrichment Matters for AI, Search, and Discovery
AI systems can't function properly when product data is incomplete.
Modern discovery, whether it’s search, filters, recommendations, or AI-generated answers, depends on depth and structure. It needs clearly defined attributes, consistent taxonomy, and enough context to understand what a product is, who it’s for, and when it should appear.
When that foundation is missing, products show up less often relative to competitors, they rank lower, or even get filtered out.
Over time, that leads to erosion of brand equity and how you are perceived by potential customers. It also undercuts all the hard work teams put in and results in a lackluster customer experience.
Some real world examples of this include:
- Products failing to appear for long-tail or conversational queries
- Filters returning incomplete or inconsistent results
- Recommendation engines surfacing less relevant items
- AI systems lacking the context to confidently promote or compare products
Teams may adopt new tools expecting better outcomes but those systems depend on the inputs they're given. And, without enriched product data, even the best AI struggles to deliver meaningful results. It's a significant risk to any retail AI investment.
As weak data continues to be used, the inconsistencies become more apparent and the gap widens between retailers who address it vs. those who do not.
For more information on how enable AI search and discovery, check out our guide to AI-ready product data.
When Should You Start Evaluating an AI PIM?
Most teams don’t wake up one day and decide to change how they manage product data. These systems are expansive, deeply engrained in how business gets done day-to-day, and take knwoeldge and training to operate correctly. A rip and replace approach is never the ideal scenario.
When products aren’t showing up where they should, search results are incomplete, and conversion rates plateau even when traffic grows, the impact moves closer to revenue. It's time to start looking at what's causing the problem.
Here are some indicators that an AI-first PIM may be worth evaluating.
When Data Becomes a Bottleneck
There’s a clear turning point in most organizations where product data stops being a background function and becomes a visible constraint.
It usually shows up in patterns like these:
- Product onboarding cycles are slowing down, even as demand to launch faster increases
- Teams are spending more time enriching data manually than driving merchandising or growth initiatives
- Supplier data quality is inconsistent, requiring repeated cleanup across the same categories
- Product content looks too similar to competitors, making it harder to differentiate
- Investments in search, personalization, or AI are not producing meaningful improvements
Individually, these issues can be managed.
Together, they point to something structural.
The system is managing data, but not improving it.
When Growth Exposes Your Limits
Growth tends to amplify the problem.
What worked at 5,000 SKUs starts to break at 10,000. Just as what was manageable for one channel becomes increasingly complex as more are added.
Expansion often introduces new pressures in a variety of ways:
- More categories, each with different attribute requirements
- More suppliers, each with different data standards
- More channels, each needing slightly different formats
At this stage, manual processes not only slow things down but they introduce inconsistency across the entire catalog that amplifies what's been wrong since the beginning. This inconsistency is exactly what modern discovery systems struggle with most.
When Data Needs to Do More Than Display
AI is the final trigger that tells a business it's time to start evaluating a solution to the problem. As soon as product data needs to support:
- Conversational search
- Recommendation engines
- AI-generated answers
- Agentic buying experiences
…the requirements change.
This goes beyond how data is arranged on a product page. This is how people are shopping now. They are using AI tools and answer engines to find the exact products for their job to be done. For your products to be seen and recommended, their foundational data needs to be:
- Structured in a way machines can interpret
- Complete enough to support filtering and comparison
- Rich enough to answer questions without human intervention
This is where legacy systems fall short. They were simply built for a different purpose and time when these advanced technologies weren't part of the retail ecosystem.
A Simple Test
One of the simplest ways to evaluate your current state is to ask, “If we stopped manual enrichment tomorrow, would our catalog still perform?”
If the answer is no, then your system relies on people to maintain data quality.
That’s the clearest signal that it’s time to explore an AI PIM.
For more information on evaluating retail AI technologies, have a look at our Retail AI Evaluation Playbook.
So you're an AI PIM Expert, Now What?
All this to say, your legacy PIM systems are still essential. They provide structure, governance, and consistency across your catalog. However, they were never designed to carry the full weight of modern commerce.
They don’t create missing data.
They don’t enrich content at scale.
They don’t prepare product data for AI-driven discovery.
That responsibility sits squarely on the shoulders of the enrichment layer.
When these systems work together, the result is a stronger foundation. Not just a catalog that is organized, but one that is complete, structured, and continuously improving.
Fortunately, most retailers don’t need to replace their PIM to move forward in a world with AI. They need to strengthen what sits around it.
An AI-first enrichment layer can plug into your existing stack, improve product data at the source, and unlock better performance across search, discovery, and conversion without disrupting your current systems.
That’s where Trustana comes in. If you’re starting to see the signs in your own catalog, it may be worth taking a closer look. You can explore how it works with a free demo whenever you’re ready.