

Back
Data Source Control: Cleaner, More Trustworthy Product Data at Scale
Product data should feel simple. A shopper clicks on something, sees the details they need, and makes a confident choice. But behind the scenes, retailers know the truth: data comes from everywhere, in every format, and with every level of accuracy. One brand calls it “color,” another calls it “shade.” One supplier gives you full details, another gives you two lines of text. If you want that data to stay clean, consistent, and ready for AI, you usually trade speed for control.
Data Source Control changes that equation.
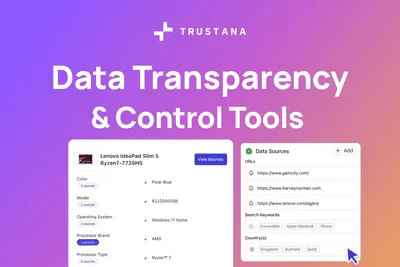
Data Source Control is the intelligence layer that tells your enrichment engine where to look when pulling product information.
Instead of letting an AI model decide on its own, letting it roam free to search across the open web, supplier feeds, or whatever data happens to be available, Data Source Control allows you to define exactly which sources are trustworthy.
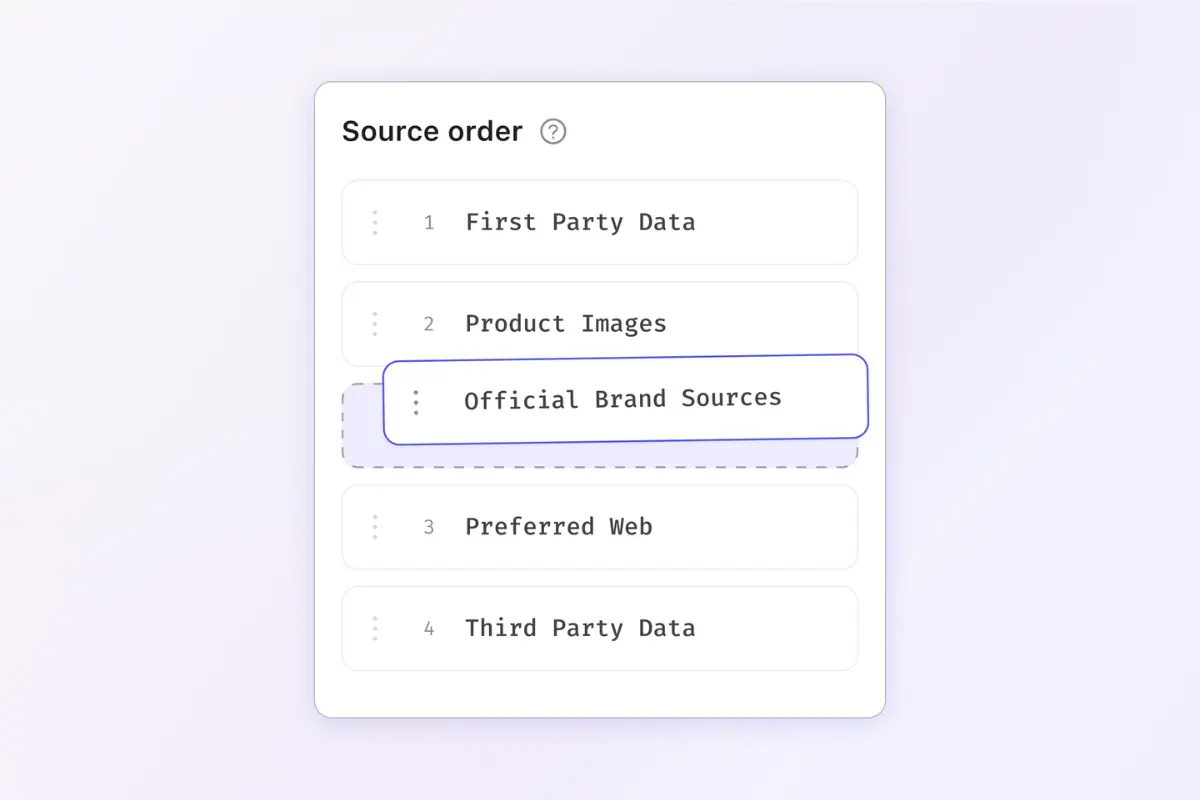
It is the mechanism(s) by which retailers can set rules for product category, by brand, or both. This means prioritizing brand-owned domains, so the system always chooses the most authoritative source first, and establishing a trusted domain list that prevents unreliable or inconsistent sources from ever influencing product data.
For retailers, the value is straightforward. When your data comes from everywhere, your teams waste countless hours cleaning, correcting, and reconciling inconsistencies before those products ever make it online.
Data Source Control removes that uncertainty by guiding AI according to your business logic. The model knows from where to pull information, how to rank sources, and what to ignore entirely. You get cleaner product data, fewer manual fixes, faster SKU onboarding, and a catalog that stays consistent as it evolves.
This is how you get confidence in your data without slowing down your digital operations. No more enrichment runs pulling questionable details from random websites. No more manual cleanup to fix small-but-important errors that slip through. Data Source Control keeps the model focused on what's imptant to your business by letting you specify trusted domains, category-level rules, and brand-first logic t every output reflects how your business actually works.
With the right guardrails, enrichment becomes a predictable, repeatable system you can trust.
Think of it as the best parts of LLMs with none of the junk that clogs up your systems and hmastrings your teams.
With Trustana’s recent release of Context Graph, retailers finally have a way to guide AI the same way they guide their teams. Instead of letting a general LLM wander through the internet and guess which information is correct, Data Source Control sets clear boundaries.
You choose which sources matter most.
You decide whether brand.com is the single source of truth.
You define how each category or brand should be handled. And the system follows those rules automatically, at scale.
If clean product data is the foundation of digital commerce, Data Source Control is the quiet superpower that keeps that foundation solid while the rest of your business moves at full speed.
Book a demo with Trustana and see how mid-market and enterprise retailers use Context Graph to deliver accurate, governed product data across every channel.
Data Source Control is a new capability within Trustana’s Context Graph that lets retailers decide which data sources are trusted when enriching or extracting product information. It gives teams more accuracy without slowing down speed-to-market.
Most product data comes from many different feeds, suppliers, and websites. Without direction, AI models can mix good sources with unreliable ones. Source control keeps enrichment aligned with your business rules so the output stays clean and consistent.
It provides the guardrails AI needs. By setting category-level or brand-level sourcing rules and prioritizing brand-owned domains, retailers ensure the model pulls data from reliable places — minimizing errors and reducing manual cleanup.
No. Data Source Control is designed to increase trustability without sacrificing time to market. Once rules are set, the system applies them automatically across large catalogs.
That’s exactly where Context Graph shines. You can define rules by brand or product category, so no matter how sources differ, the enrichment process stays structured and predictable.
By removing uncertainty. Instead of your team reviewing every output for inconsistencies, Data Source Control ensures the AI model stays aligned from the start, allowing thousands of SKUs to be enriched faster with fewer corrections.
It’s especially powerful for AI use cases, but the benefits extend across search, navigation, SEO, PDP quality, and any workflow that depends on clean product data.


