For many industrial B2B businesses, product data does not live on the web.
It lives in PDFs.
That can be in the form of detailed product catalogs, specification sheets, technical tables, and manuals. These are seen as the most complete and trusted source of product information available.
In most cases, they are the only source. And, despite their importance, PDFs have yet to find their way into scalable product data enrichment workflows.
This gap has real consequences. High-value industrial deals stall. Digital buying portals and e-commerce storefronts remain incomplete. Teams are forced into manual workarounds that don’t scale.
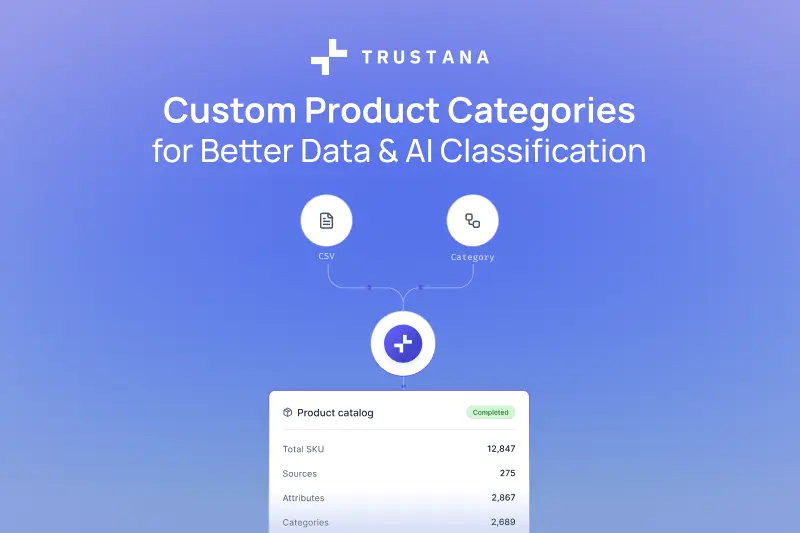
Trustana is solving those problems by introducing the capability to utilize PDFs as a product data enrichment source.
Now, industrial catalogs that were previously out of reach are accessible with an industry-leading, first-to-market solution for using PDF data as an enrichment source at scale.
Why this is Needed
Industrial and B2B manufacturers maintain extensive catalogs, often exclusively in PDF format. These catalogs typically fall into a few common types:
- Single product, single brand documents
- Multi-product, single brand catalogs
- Table-driven catalogs with single or multiple brands
- Retail-style multi-brand catalogs
While these PDFs are brand-specific and already contain structured information, their structure is largely inaccessible for enrichment, especially at scale.
A single PDF page may contain 20 to 30 products. One file may represent hundreds of SKUs. Attributes may be organized neatly in tables, but not isolated by product. Traditional enrichment tools and PIMs are not designed to interpret this format. As a result, they aren’t able to utilize what becomes an untapped enrichment source.
How PDFs Break Existing Enrichment Workflows
Businesses know their PDFs are valuable, but they lack a reliable way to utilize them due to:
- No efficient extraction path - Product tables and specifications are embedded in PDFs with no direct way to extract structured data.
- Manual screenshot workarounds - Teams resort to taking screenshots of PDF pages and uploading them as images just to trigger enrichment flows.
- Poor SKU isolation - One PDF may contain data for dozens of products, making it difficult to map attributes cleanly to individual SKUs.
- High operational overhead - Building and maintaining file management and parsing logic inside a PIM requires significant time and resources.
- Data quality risk - Manual extraction introduces errors, leads to missing attributes, and results in inconsistent catalogs.
All this compounds the simple fact that specialized industrial products are not readily available through web enrichment and, without PDF processing, enrichment simply stops. This leaves businesses in a difficult position.
How Teams Try to Solve It Today
Most teams know the workaround is not sustainable. But, what choice do they have?
They manually extract data. They screenshot pages. They copy and paste tables. They upload images with their fingers crossed in hopes that AI can interpret them without too much cleanup on the other end of enrichment. They settle for poor results simply because there isn’t a better alternative.
As a result, slower launches, incomplete catalogs, and lost revenue opportunities are begrudgingly accepted as part of the process.
There are existing products that try to fill the gap, but they all fall short in their own way. The existing options include:
- RAG style “Chat with your document” - No automation component exists. It may be added onto an AI workflow, but that's developer-dependent and a heavy lift.
- PDF-to-Structured-Data - Heavy user effort is required, and the output is in JSON format, so users then need to decide how to utilize or integrate it themselves after the output is generated.
- Traditional PIM/MDMs - These offer manual or rule-based file associations but fail to use/process the file content for any task. More advanced ones have attribute by attribute prefilling ‘suggestions’ but fall short of true automation as part of the enrichment process.
Until today, there has been no no-code, batch-focused, low-effort file data retrieval tools providing and end-to-end process for the b2b segment.
How Trustana Unlocks PDF Product Data
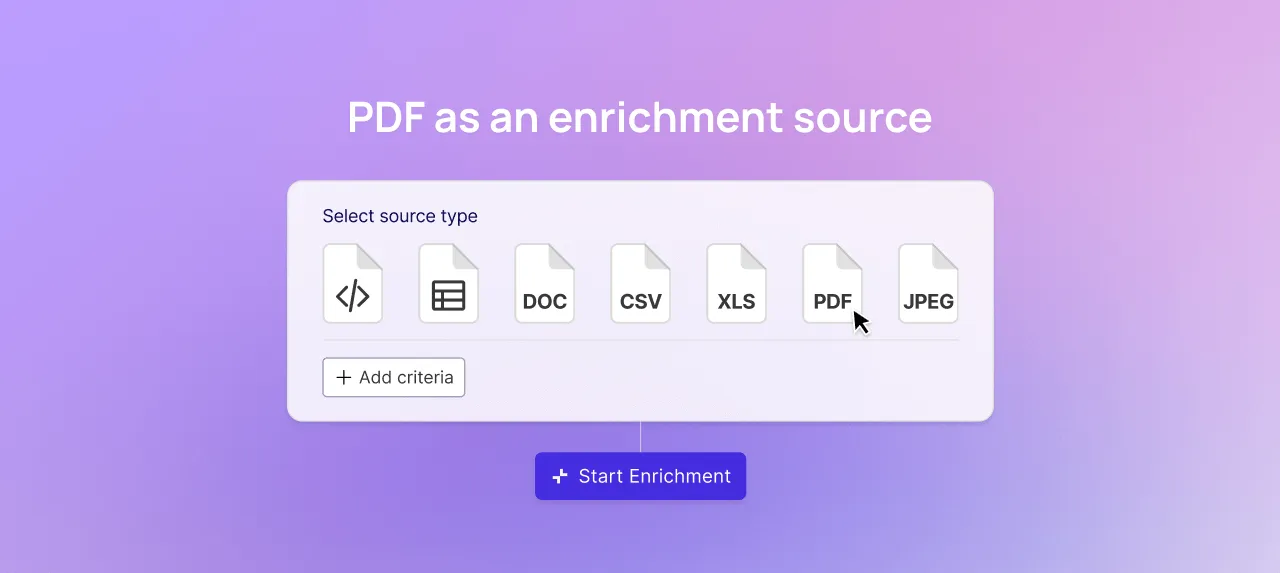
Automated PDF catalog processing is now available in Trustana and can be used as part of your enrichment workflows.
This capability is purpose-built for industrial B2B customers whose most accurate product data lives in PDFs and cannot be sourced from the web. But really, anyone who wants to use PDFs as a source can leverage this invaluable feature.
Using advanced retrieval-augmented generation (RAG) and LLM techniques, Trustana can extract factual product attributes directly from PDF sources with 95 percent or higher accuracy, while preserving trust, traceability, and structure.
This is not a side workflow or a workaround. PDF processing is fully integrated into Trustana’s enrichment layer.

How PDF as an Enrichment Source Works
The PDF enrichment flow is designed to feel familiar.
When products and attributes already exist, and PDFs are stored within the account, users can initiate PDF processing directly after category selection, similar to Trustana’s existing AI enrichment flows.
Behind the scenes, Trustana:
- Identifies and isolates individual products within dense PDF documents
- Extracts structured attributes and specifications
- Maps extracted data to existing product and attribute schemas
- Feeds results into the same enrichment workflows users already rely on
The experience remains consistent, while the data source expands significantly.
Built for Scale, Accuracy, and Enterprise Reality
This capability is designed to handle real industrial complexity. Trustana supports:
- Processing of 100+ product catalogs efficiently
- Catalogs exceeding 200 pages per file
- PDFs containing mixed product layouts and dense tables
Why This Matters
This release unlocks three core outcomes for industrial and B2B marketing teams.
Automated Processing
What once took hours of manual work can now be completed in under 30 minutes, with accuracy exceeding 95 percent across attributes.
Unlocked Revenue
Organizations can finally utilize specialized industrial catalogs that previously brought deals toa standstill, enabling faster onboarding of complex SKUs and product lines to support sales.
Quality Assurance
PDFs are essentially first-party, brand-owned data. As an enrichment source, they carry the highest trust ranking and outperform web-scraped alternatives in completeness and reliability.
First-to-Market, We Build What Comes Next
Trustana is the first product data enrichment platform to bring scalable, automated PDF processing into enrichment workflows.
While most PIMs and enrichment tools stop at the web, Trustana extends enrichment to where industrial data actually lives. This advancement not only closes a gap in legacy product information management, it sets a new standard for how specialized product data should be handled.
See It in Action
Working with data that lives in PDFs doesn’t have to be a bottleneck. With Trustana, is becomes a competitive advantage. If your product data lives in PDFs, this capability changes what is possible.
Book a demo with an expert to see how we are unlocking industrial catalogs and breathing new life into stalled deals.